Replication and Deployment in Zones
M3DB supports both deploying across multiple zones in a region or deploying to a single zone with rack-level isolation. It can also be deployed across multiple regions for a global view of data, though both latency and bandwidth costs may increase as a result.
In addition, M3DB has support for automatically replicating data between isolated M3DB clusters (potentially running in different zones / regions). More details can be found in the Replication between clusters operational guide.
Replication
A replication factor of at least 3 is highly recommended for any M3DB deployment, due to the consistency levels (for both reads and writes) that require quorum in order to complete an operation. For more information on consistency levels, see the documentation concerning tuning availability, consistency and durability.
M3DB will do its best to distribute shards evenly among the availability zones while still taking each individual node’s weight into account, but if some of the availability zones have less available hosts than others then each host in that zone will be responsible for more shards than hosts in the other zones and will thus be subjected to heavier load.
Replication Factor Recommendations
Running with RF=1 or RF=2 is not recommended for any multi-node use cases (testing or production). In the
future such topologies may be rejected by M3DB entirely. It is also recommended to only run with an odd number of
replicas.
RF=1 is not recommended as it is impossible to perform a safe upgrade or tolerate any node failures: as soon as one
node is down, all writes destined for the shards it owned will fail. If the node’s storage is lost (e.g. the disk
fails), the data is gone forever.
RF=2, despite having an extra replica, entails many of the same problems RF=1 does. When M3DB is configured to
perform quorum writes and reads (the default), as soon as a single node is down (for planned maintenance or an unplanned
disruption) clients will be unable to read or write (as the quorum of 2 nodes is 2). Even if clients relax their
consistency guarantees and read from the remaining serving node, users may experience flapping results depending on
whether one node had data for a time window that the other did not.
Finally, it is only recommended to run with an odd number of replicas. Because the quorum size of an even-RF N is
(N/2)+1, any cluster with an even replica factor N has the same failure tolerance as a cluster with RF=N-1. “Failure
tolerance” is defined as the number of isolation groups you can concurrently lose nodes across. The
following table demonstrates the quorum size and failure tolerance of various RF’s, inspired by etcd’s failure
tolerance documentation.
| Replica Factor | Quorum Size | Failure Tolerance |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
Upgrading hosts in a deployment
When an M3DB node is restarted it has to perform a bootstrap process before it can serve reads. During this time the node will continue to accept writes, but will not be available for reads.
Obviously, there is also a small window of time during between when the process is stopped and then started again where it will also be unavailable for writes.
Deployment across multiple availability zones in a region
For deployment in a region, it is recommended to set the isolationGroup host attribute to the name of the availability zone a host is in.
In this configuration, shards are distributed among hosts such that each will not be placed more than once in the same availability zone. This allows an entire availability zone to be lost at any given time, as it is guaranteed to only affect one replica of data.
For example, in a multi-zone deployment with four shards spread over three availability zones:
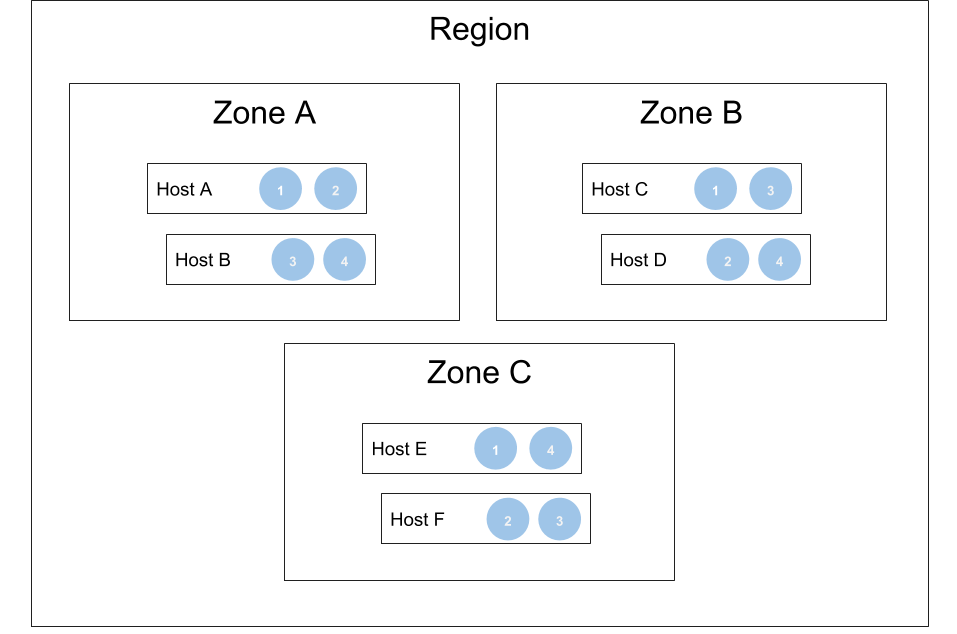
Typically, deployments have many more than four shards - this is a simple example that illustrates how M3DB maintains availability while losing an availability zone, as two of three replicas are still intact.
Deployment in a single zone
For deployment in a single zone, it is recommended to set the isolationGroup host attribute to the name of the rack a host is in or another logical unit that separates groups of hosts in your zone.
In this configuration, shards are distributed among hosts such that each will not be placed more than once in the same defined rack or logical unit. This allows an entire unit to be lost at any given time, as it is guaranteed to only affect one replica of data.
For example, in a single-zone deployment with three shards spread over four racks:
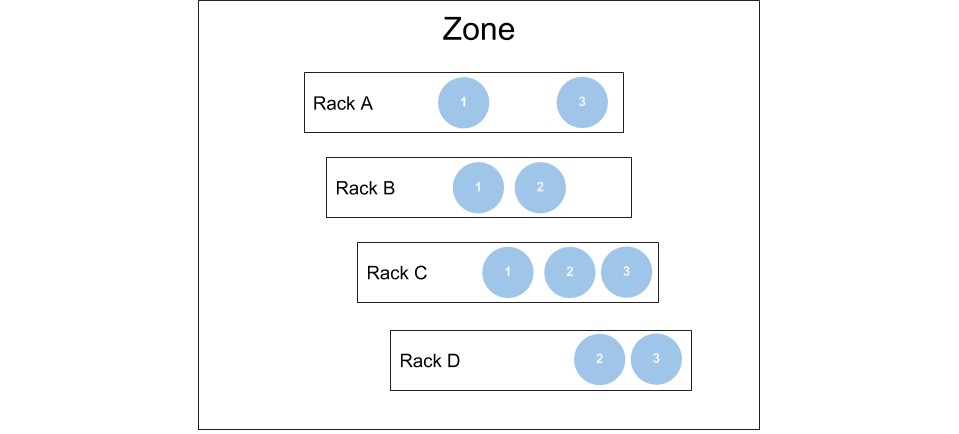
Typically, deployments have many more than three shards - this is a simple example that illustrates how M3DB maintains availability while losing a single rack, as two of three replicas are still intact.
Deployment across multiple regions
For deployment across regions, it is recommended to set the isolationGroup host attribute to the name of the region a host is in.
As mentioned previously, latency and bandwidth costs may increase when using clusters that span regions.
In this configuration, shards are distributed among hosts such that each will not be placed more than once in the same region. This allows an entire region to be lost at any given time, as it is guaranteed to only affect one replica of data.
For example, in a multi-region deployment with four shards spread over five regions:
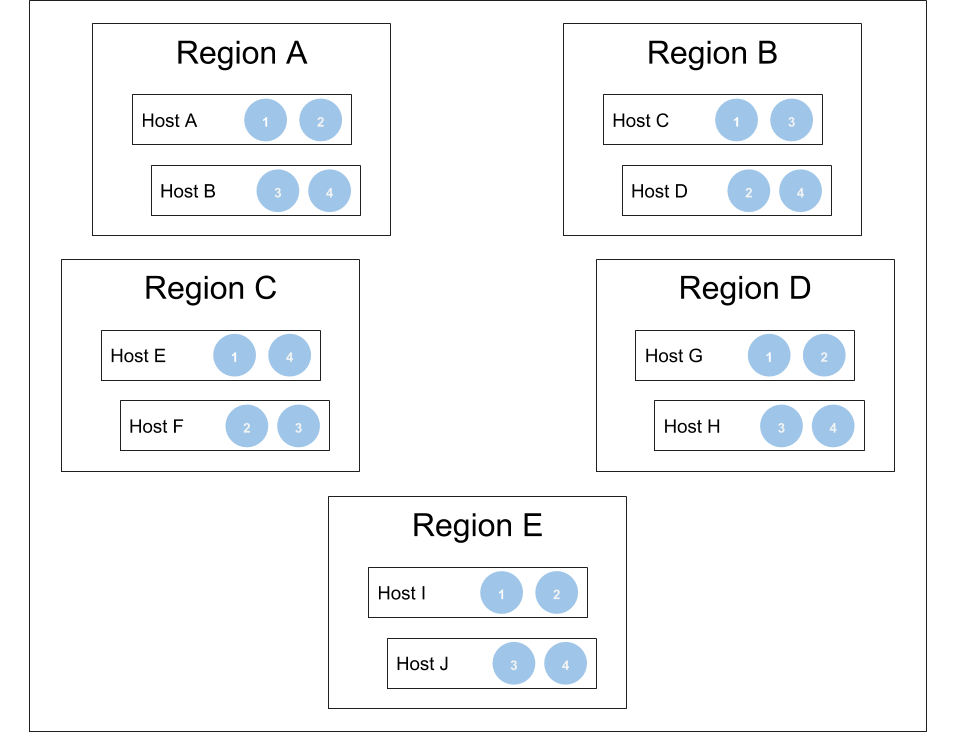
Typically, deployments have many more than four shards - this is a simple example that illustrates how M3DB maintains availability while losing up to two regions, as three of five replicas are still intact.